Experiments
I still don't have acces to the model with my account (I still don't have any membership). But Juan opened a session on a browser on my tower so I could start messing around a bit. I didn't go too far because he was in San diego, only had access to a 600 images model instead of the 3000+ one. I met nik, who had acces to it, and seemed to have better results than me. I also didn't want to mess with Juan's work.
So here is what I did:
Character design
I started with trying to design one of my character, the generalissime. I already deisgned him, it is a SEXY BADASSS. I wanted to see him in different action poses. Here is what he looks like:




I tried to remix an existing image I generated in midjourney about a year ago. The model was good to transpose an existing image into my style, but I had a hard time having his big breasts. I learned that I could not write "big breast". I tried various synonyms, I also tried the magic fill, without satisfaction.
The best I could come up is this:

But it doesn't have the "sexy badass" attitude of the character. I probably miss prompting skills, I will surely try again.
- To try: it's very hard having a recuring character. I'd like to train a custom model with a few images of the character, with his name in the description. Nik gave me nice insights ("draw him doing something, not posing; as you can describe what he's doing in the description")
LOCATION DESIGN
I remember having a very hard time last year with this specific design: in my sci-fi movie, there is a scene in a futuristic bath, that has the shape of a mushroom. The water showers from the mushroom's cap. It's very hard to describe, it's more of a visual idea. The nearest I had with midjourney was this, and it still is not exactly what I had in mind. It took HOURS to generate this:

I tried to remix with my styl, I was not convinced:

I then tried to generate an image with the default model, to avoid using a midjourney image. It was hard (but I'm not very skilled with prompting, I miss experience). Then tried to transpose into my style. I also tried with only prompting. The whole experience was not satisfying. (see notes about word prompting below)




ABOUT USING WORD PROMPTS
I worked with midjourney for a year or so (not full-time!), and I came to the conclusion that I prefered not using words. I almost never used the prompt box. What I used the most was the blending tool: choose two images, blend them. I wanted a sc-fi train, I blended a train image with an asparagus image. It worked way better that using the words, probably because I chose which asparagus and which train - or maybe, which asparagus feel, and which train feel.
I could not blend for a lot of generations (the more we go, the more it loses textures), but I can say this tool generated the most interesting stuff. Because creative and surprising stuff would emerge, that are difficult to describe in words. The mushroom bath is a good example. It's no mushroom, it just has a shape that vaguely resembles to a mushroom. The word really limits the possibilities. The visual is more subtle, has more complexity.
MAGIC PROMPT
Would it be possible to edit the magic prompt before sending the request? I read the magic prompt afterwards and it sometimes have style or color specifications that don't match with the custom model (or what I am looking for).
TURBO VS QUALITY
Using the football-fantaisie model, there are no great textures or details, so I didn't see difference between turbo and quality. Therefore, I will stick to turbo.
REDRAW I
Having the model generate a very specific idea I have in mind is hard, very frustrating, it doesn't work (character, location). But when what I have to design is very blurry in my mind, I think AI could help.
There are police drones in my animation movie. I still don't know what they look like. I started with a very simple description + magic prompt, and became more and more specific.
It had some very good ideas sometimes. But it was always a detail on the image, never the whole image. The shape of the drone, an idea of how to draw the propellers, the flashing lights... so I took a pen and a paper and started to sketch and blend togheter ideas that were generated - a little bit of this, a little bit of that. This was a fun exercice, and it was useful. It helped me design the drones (I still haven't chosen the final design).




My sketches:

I just wonder if I could have done it without AI?? Caricatural sci-fi police drones don't exist in real like, so I guess I couldn't have used google image.
The other question is: to I really need the football-fantaisie model? The answer is: sometimes yes (as for the propeller), sometimes no (I can redraw details from an image generated in the default model)
What I really like about using the model trained on my style, is that is has nice ideas on how to schematise objects. Schematizing is a hard part of drawing: how to you synthetize the complexity of reality? The model offers a nice solution that I would not have thought of. For now, little parts of the images are interresting, never the whole composition.
REDRAW II
The resolution of the generated images is very low. I was thinking of printing a generated image on a t-shirt as a christmas gift for Juan. I did a test and it was ok. But to me it seemed a bit oof because the position was "centered-not-centered" (the robot seems in the midle, but look at the sky). When printed on a shirt, it seemed off.
GENERATED IMAGE:
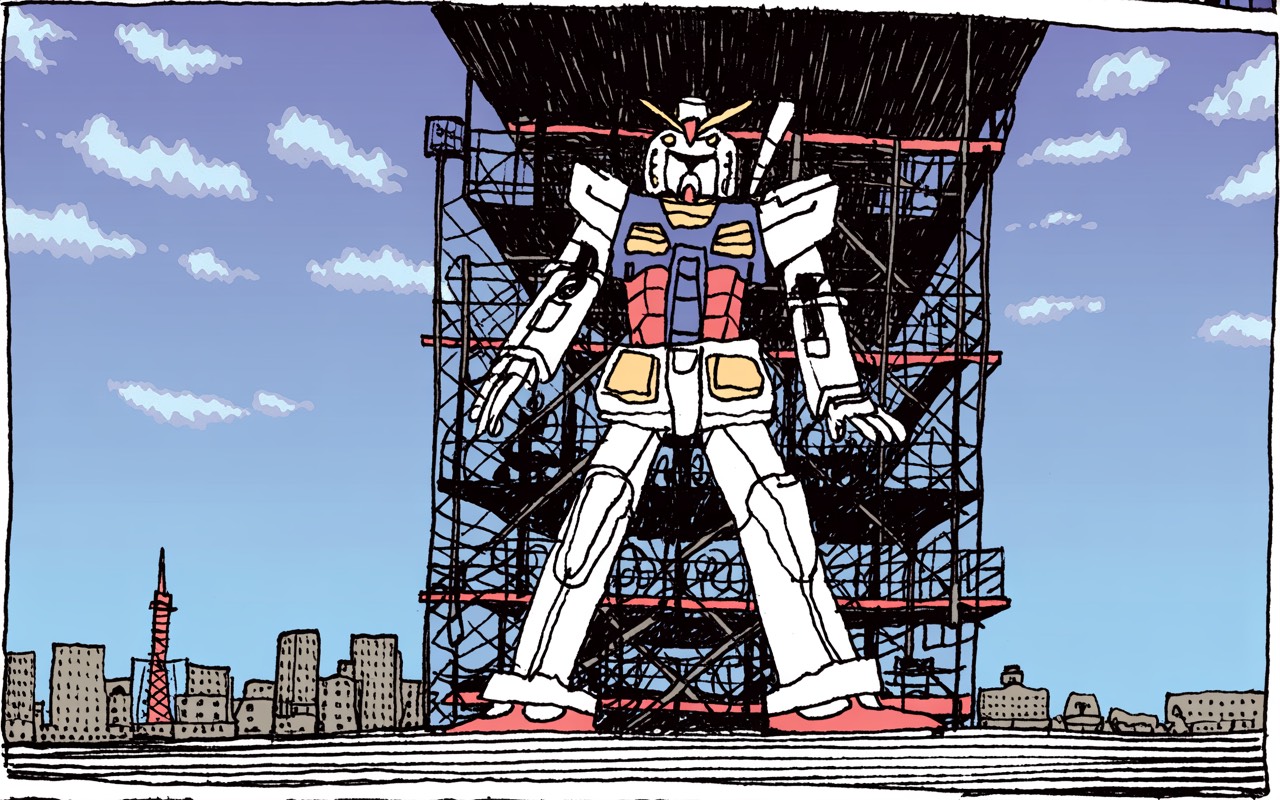
but I really liked the pose, and the small building details at the bottom. "what if I try to redraw it? I'll then have a bigger resolution."
(I tried the same before with some fire, generated in another image. I like the schematisation of fire it offered, I really liked the shape, and I wanted to reproduce this pleasing schematisation of fire with my hand, in another image).
Well, It was very hard! When we look at the AI image, it seems to make sense, but when we try to reproduce it by hand, it... kinda... have no system, no pattern in it. We have to create it ourselves on what we see. With the fire, I invented a system. With the gundam metallic structure, I said to myself: "what the hell! I'll try doing illogical stuff like in the reference" - It was very hard, and in the end, it didn't look that good.
DRAWN BY HAND (colored in photoshop, color picking the generated image):
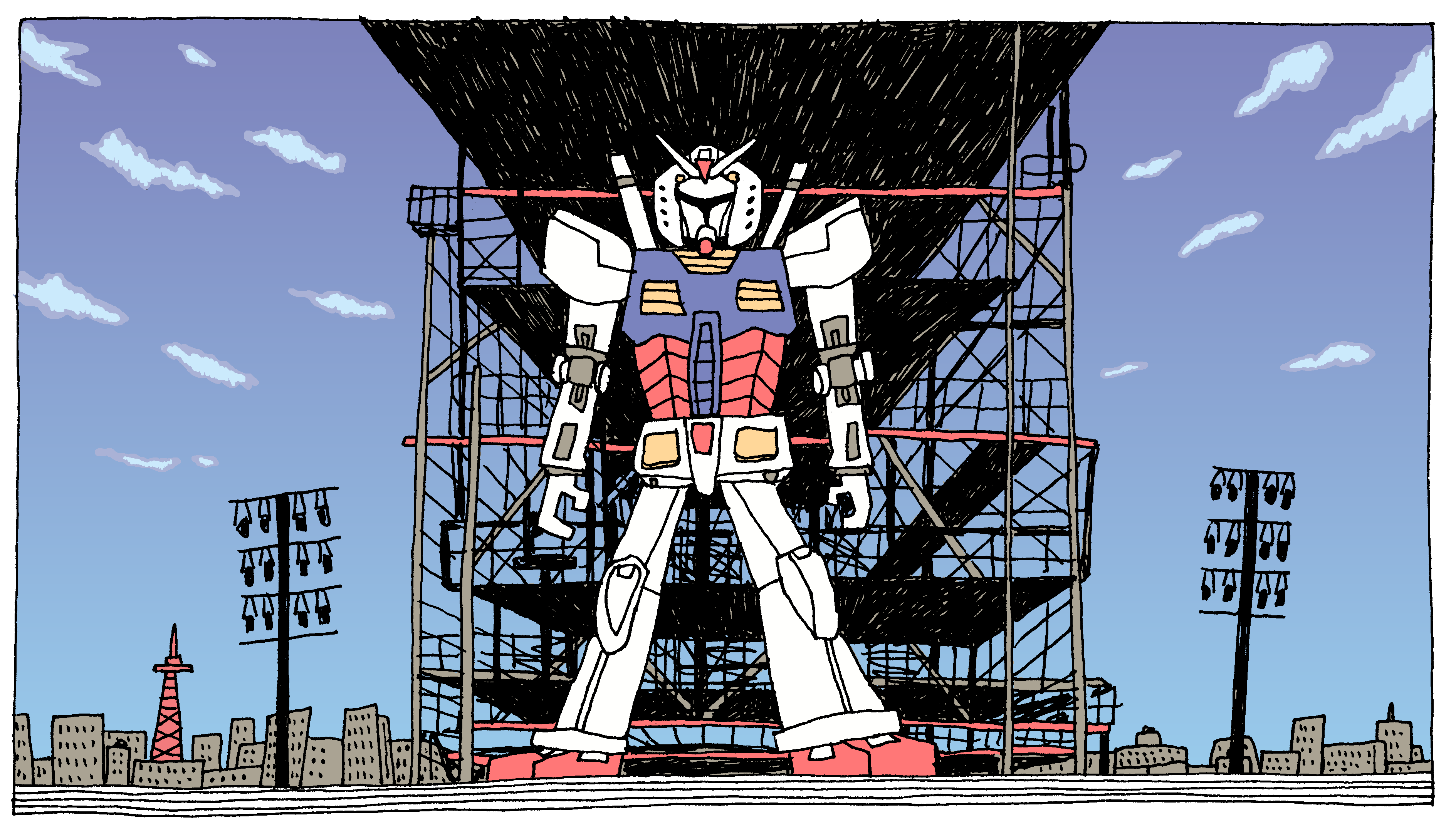
I'm thinking I would probably have had a better result having a real photograph of the yokohama gundam as a reference for drawing, instead of the AI one. BUT: with a reference photograph, I wouldn't have the beautiful shcematic cityscape in the bottom of the image. This is what I was looking for.
WHAT'S NEXT
This is the result of only 3 days of experiments. I wanted to work on this last week, but Juan and me (and my daughter) got terribly sick, so I had to put that on hold. I also was waiting to have my own access to the right model to continue.
The main thing I would like to try is to make a custom model that is a derivate from the Football-Fantaisie model, in which I train in with different caracters having a name. I would like to see the possibilities of storyboarding with recurring characters and locations.